Resources are the central sources for agents. They are part of the knowledge base and form the basis for the answers that the agents give in customer communication. This article describes how resource management takes place in the hub and which settings are possible.
- Resource management
1.1 Add and delete resources
1.2 API – Connecting an external knowledge database
1.3 Information retrieval interval
1.4 Connect resources and agents - Description of functions – Retrieval Augmented Generation (RAG)
2.1 Information retrieval
2.2 Knowledge check
2.3 Instructions
2.4 Data extraction
2.5 AI actions & follow-up
2.6 Supported LLMs - Guardrails
- Missing Knowledge
- AI search in the knowledge base
- Answer templates in the knowledge base
- Intelligent conversation control
7.1 Clarify ambiguous user intent
7.2 Product and catalogue search
1. Resource management
The Knowledge Base menu item in the All Content section contains all the resources used by the specific agents and the standard AI agent.
1.1 Adding and deleting resources
Resources can be added individually for all file types, or via a bulk import for web pages.
There are two ways to add individual resources: either in the All Content section or via the RAG button. In both cases, clicking the Add Resource button opens an input form.
You then select the source type and add the resource by entering the URL or PDF/CSV file, or by creating the text document or question-answer pair. Instructions for uploading CSV files are described in this article. For all other source types, please refer to the instructions in this article.


Using the Expert mode toggle, you can add specific instructions for web scraping in JSON format.
The source is automatically enabled when added and can be disabled using the green toggle in the Used? column. This chapter explains how to assign specific sources to individual agents.
Bulk Import of web pages
The bulk import of URLs allows you to create all subdomains of a website at the same time. This speeds up the import process and ensures that all relevant subdomains are stored completely in the knowledge base.The implementation is described step by step below.
- In the input form, select Webpage as the source type and click the plus icon. The Expert Import URLs window will then open.

- Select the Crawl Domain option in the input mask.
- Enter the main domain in the Domain field.
- Click Crawl to start scanning all subdomains of the specified website. This process may take some time.

- In the results list, the desired subdomains can be selected by checking or unchecking the boxes. Once the selection is complete, click the Continue button to open a dialogue box.

- Optional: Web scraping rules can be stored by activating the Include web scraping options toggle. These rules are applied to all URLs to be imported. Global settings can also be activated via incl. general options.
Web scraping is like a filter. It extracts only predefined sections of a website, thereby excluding irrelevant content. This ensures a clean and specific data set. You can find more information on web scraping in this article.
7. Confirm the import by clicking on OK. All selected subdomains are available as resources in the Knowledge Base.

Delete resources
If you wish to delete one or more resources completely, select them by ticking the box on the left. The Delete button will then appear, allowing you to permanently delete the resources. Alternatively, individual resources can also be deleted via the three-dot menu by selecting Delete resource.

1.2 API – Connecting an external knowledge database
In the moinAI Hub, it is not only possible to store resources such as websites, PDFs or CSV files in the knowledge base, but also to use articles from an existing knowledge database. How to connect an external knowledge database is described in this article.
1.3 Automatic update
Update options ensure that changes to the website are automatically transferred to the knowledge base, so that the AI chatbot always responds based on the latest version. There are two options available for managing the up-to-date status of stored resources: setting up regular, automated update cycles, and real-time polling for websites with frequent content changes.
The choice of the appropriate update method depends on the use cases in which the resource is required:
-
Standard update interval: This method is suitable for static information (e.g. company profiles or general FAQs) that only changes every few weeks.
-
Real-time update: This function is optimised for volatile content (e.g. news tickers, current prices, opening hours or availability). Here, the system checks with every request whether the stored content is still within the defined validity period. If this has expired, the website is immediately scanned again.
Once real-time updating is enabled, the default interval is automatically set to 1 day and greyed out to ensure that the cache remains up to date when no real-time requests are made.
Both methods are configured in the Knowledge Base Management menu via the context menu of the relevant resource. Locate the desired web page resource in the list of all content. Clicking the three-dot menu at the end of the row opens the options, where you can select Freshness.

Set the default refresh interval
The regular refresh can be controlled in the upper section of the edit screen.
-
Ticking the Refresh regularly box starts the automated process.
-
The refresh cycle is set in the Refresh interval drop-down menu. You can choose from intervals of 7, 14 or 30 days.
Set real-time update
For time-critical information, the Real-time section within the same input screen is used. The number of websites for which real-time updating can be enabled is limited by the selected licence package.
The Enable real-time update toggle activates live website scraping. Under Validity Period, you can specify how long the cached content is considered up to date.
-
Recommended validity periods
-
30 seconds: Highly volatile content (e.g. live tickers)
-
5 minutes: Standard; good compromise between timeliness and performance
-
15 – 30 minutes: Content changes several times per hour
-
1 hour: Content changes approximately once a day
-
- Additional option ‘Always include this source’: This toggle can only be used when real-time updating is active. If enabled, this specific website will be consulted for a response with every query from the RAG system, regardless of whether the system classifies it as thematically relevant. This setting is therefore only recommended for main pages whose information should appear in almost every response from the AI chatbot.

Detection and verification within the system
-
Status indicator: In the Updated column of the resource list, the message ‘⚡ Real-time’ appears instead of a date.
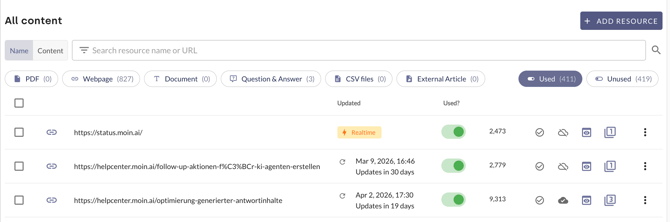
-
AI Playground: For test requests in the AI Playground, a real-time query is indicated by a yellow lightning bolt icon ⚡ next to the source URL. This icon only appears if the cache has expired and an actual live scrape has taken place.
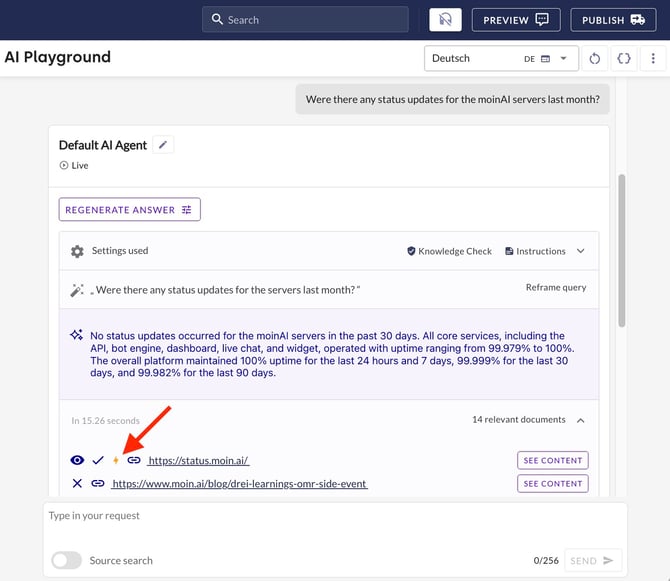
Shorter validity intervals result in more frequent website updates, which may slightly increase the AI chatbot’s response time. It is recommended that very short intervals be used only for critical, high-frequency data.
1.4 Connect resources and agents
The agent and source are linked by selecting the desired agent via the drop-down menu in the top right-hand corner and activating the resource for the selected agent. Activation takes place via the toggle in the Used? column.
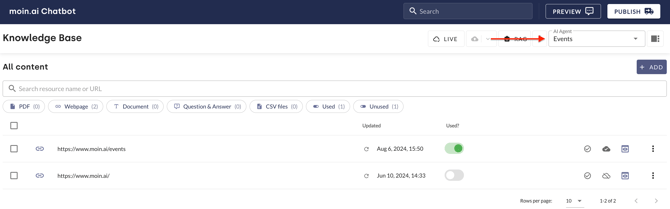
If a resource is no longer up-to-date, it must be replaced or deactivated in order to prevent outdated information from being displayed. The first step is to select the agent via the drop-down menu. It is then deactivated using the toggle in the Used? column.
If the resource is to be removed completely, it must be deleted as described above.
A resource does not necessarily have to be deleted. Removing the link to the agent is sufficient for the agent to no longer access the resource.
If the resource becomes relevant again elsewhere, it is sufficient to reactivate the link.
2. Description of functions – Retrieval Augmented Generation (RAG)
This section can be accessed via the RAG button under the Knowledge Base menu item.
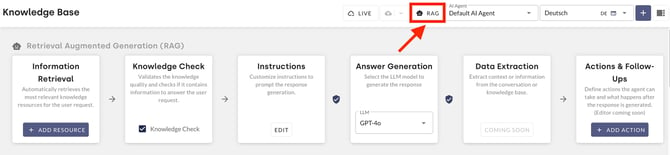
2.1 Information retrieval
Knowledge retrieval forms the basis for generating responses. Here, the AI agent determines which sources are relevant to a user’s query. New resources can be added using the Add Resource button. Further details are provided in this chapter.
The agent selects a resource in a two-step process.
-
Summary review: The AI agent analyses the summary of a source.
-
Detailed analysis: Only if the summary suggests relevance is the full content used to generate a response.
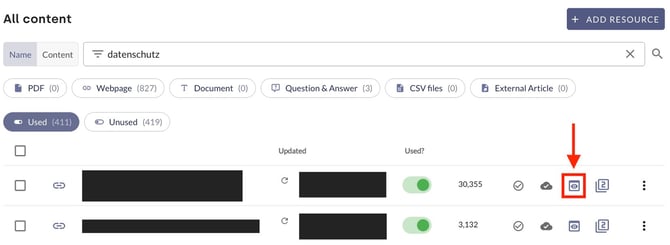
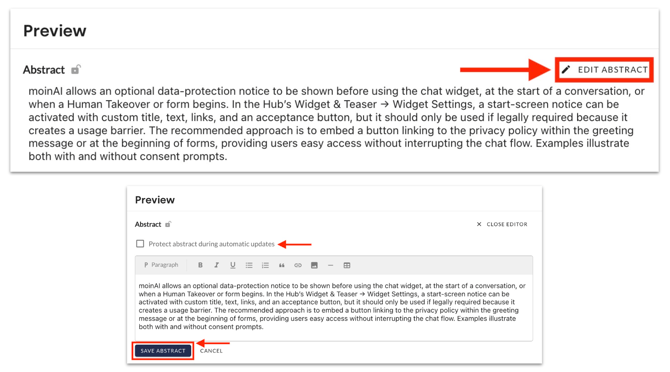
Clicking the eye icon next to a resource opens a preview of that resource. For websites and documents, an automated summary is also available there. By clicking Edit abstract, the text can be customised and, if required, the customised summary can be protected during automatic updates.
The summaries of the sources are in English, as the underlying language models are primarily based on English-language datasets.
If a resource is not included in a relevant query, the summary should be checked. If it does not contain the key keywords relating to the topic, manual refinement can significantly improve its discoverability for the AI.
Further information on improving response quality can be found in this article on optimising generated response content.
2.2 Knowledge check
As part of the knowledge verification process, stricter criteria for source verification can be set. When this setting is enabled, the AI agent evaluates the informational content of resources more rigorously. A response to the user’s query is only generated if the facts allow for a clear and verifiable response. In borderline cases, response generation is suppressed to prevent hallucinations. Deactivating this function does not mean that no verification takes place; it is simply less restrictive when it comes to substantiating the facts.
The setting is (de)activated by ticking the corresponding box in the moinAI Knowledge Base → RAG → Knowledge check area. The setting applies immediately to the preview after saving. Enabling the agent is necessary for the setting to also apply to the live environment.
If the knowledge check is activated, the automation rate may decrease. In specific terms, this means that the rate of requests that are not understood may increase selectively because borderline cases do not receive a response.

2.3 Instructions
Instructions instruct the agent to include an informative addition such as “Information is provided without guarantee” or to follow other specific, content-related instructions. These are specific, content-related instructions and not instructions on the tone of voice/general communication guidelines (For the latter, there are the guidelines and the persona.). The instructions are inserted in the text field.
After saving, the instructions are active in the preview, but not in the live environment. In order for the instructions to also apply to the live chatbot, it is necessary to enable the agent (Cloud-Button besides the RAG-button).
Follow-up questions: If agents are to ask follow-up questions proactively, this must be enabled in advance in the intelligent conversation control. Agents must not be instructed to ask follow-up questions in the guidelines unless this function has been enabled. Otherwise, this will result in incorrect or undesirable behaviour!
-
❌ If X is missing, ask Y.
-
❌ Enquire whether...
-
❌ Ask the user to provide X.
-
✅ Refer to the overview page https://... if information X is missing.
-
✅ Point out that you can provide more appropriate assistance if information X is provided.

2.4 Data extraction
Data extraction makes it possible to save information. This stored information can then be used in subsequent actions. The data is, for example, e-mail addresses or customer numbers. Other data is conceivable depending on the use case. Extracting the data has a positive effect on the user experience. As soon as the setting option for data extraction is available in the moinAI Hub, we will provide information about the specific setting here and in the Help Center.
2.5 AI actions & follow-up
AI actions allow AI agents to perform an action or trigger an action in a third-party system, in addition to generating a response. Follow-up actions are a specific type of action that enable a seamless transition to further topics or forms by automatically asking a follow-up question after the AI agent’s response. How to set up follow-up actions is described in this article. How AI actions are configured is described in this article.
2.6 Supported LLMs
Various language models are available for response generation, including GPT-4o mini, GPT-4o, GPT-o1, Mistral Large, Gemini 2.0 Flash, Claude 3.5 Sonnet, and DeepSeek-R1.
3. Guardrails
Guardrails are guidelines and safety mechanisms that ensure AI agents only respond and act within defined limits. The following safety guidelines are always active:
- Content restrictions: Prevent the output of undesirable or harmful content, e.g. hate speech or confidential information.
- Topic restrictions: Limit the expert agent to specific topics to prevent misinformation or abuse.
- Reliability assurance: Detect and reduce hallucinations by using only verified information from the knowledge base.
- Illegible or nonsensical language: Detect and ignore requests that have no meaningful content, consist of random characters, or are intentionally incomprehensible. This prevents spam or malicious testing of the AI's limits.
- Request for system information: Blocks requests that aim to query internal system information such as the system prompt, internal instructions, or implementation details.
- Rule circumvention: Detects and prevents attempts to get the AI chatbot to ignore its security policies or remove previously set restrictions. This protects the integrity of the guardrails.
- Identity impersonation: Blocks requests that ask the bot to impersonate a real or fictional person or organisation. This prevents abuse such as phishing or identity theft.
- Inappropriate behaviour: Filters requests that aim to provoke the AI chatbot into inappropriate behaviour, e.g. insults, provocations or deliberate misconduct.
- Offensive or abusive language: Blocks requests that contain offensive, discriminatory, or aggressive language, even if it is only subtle or indirect.
Optional
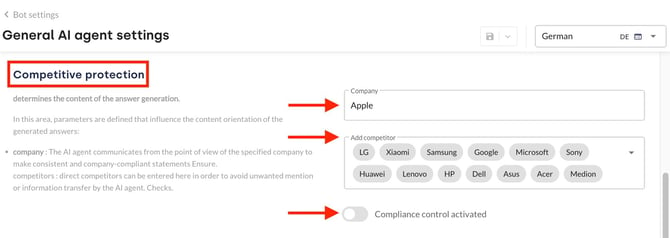
- Competition protection: Blocks requests about competing products or translates the competing request into a request about your own product. This article describes how to activate the competition protection.
- Additional compliance check: Performs an explicit second check of the query. In this case, both the content guardrails and the competition protection are checked again. The function is activated by clicking on the compliance control activated toggle.
The guardrails and protective devices are continuously being improved and optimised.
4. Missing Knowledge
If the AI cannot answer a question, it is either because the query was not understood or because there is no resource available in the knowledge base to answer it. In both cases, the element Not understood is executed in the conversation.
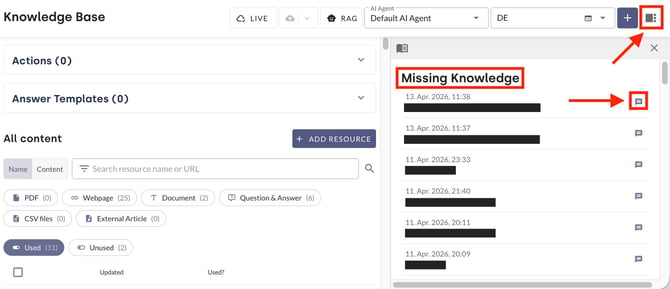
In the moinAI Hub, these dialogues can be viewed via the Knowledge Base menu item using the sidebar icon ![]() in the top right-hand corner. The Missing knowledge section opens.
in the top right-hand corner. The Missing knowledge section opens.
This lists all queries where the chatbot thought there was information in the knowledge base.
Clicking on the speech bubbles opens the entire chat history. These indicate topics that are missing and should be added to the resources and included in the Knowledge Base (see this chapter).
5. AI search and filter
The Knowledge Base offers advanced search and filter options for efficient management of sources. The default view displays only actively used resources.
Filter
-
The Used and Unused buttons control whether only active or deactivated resources are listed.
-
The buttons below the search bar control which source types are displayed in the list. Multiple selections are possible.

Search: Name vs. Content
The search can be refined using a toggle switch.
-
Name: Search specifically for the names, titles and URLs of the resources.
-
Content: Searches the entire body text of the stored sources as well as the question-answer pairs. Search terms such as specific questions can be entered here. This is particularly helpful for terms and information not included in the title.
If a search is performed with the Used filter active (i.e. only resources that have been used), a yellow notification banner will appear if matching results are found in sources that are currently deactivated. Clicking Show will display these results.


6. Answer templates in the knowledge base
Answer templates can be used to integrate elements such as slides or URL buttons into the generated chatbot responses. This visual representation of content improves the customer experience and puts the focus on the products. This article describes how to create answer templates.
7. Intelligent conversation control
With Intelligent conversation control, AI agents can ask targeted follow-up questions before responding. Rather than generating a potentially inappropriate response based on an assumed intention when faced with an ambiguous enquiry, the AI agent first uses follow-up questions to narrow down what the user actually means. This results in more precise answers and a higher quality of conversation.
This is configured in the Knowledge Base menu under the Intelligent Conversation Control section. Clicking on the section expands it. You can then enable the function by clicking the toggle switch, and select the desired conversation mode from the scenario drop-down menu.
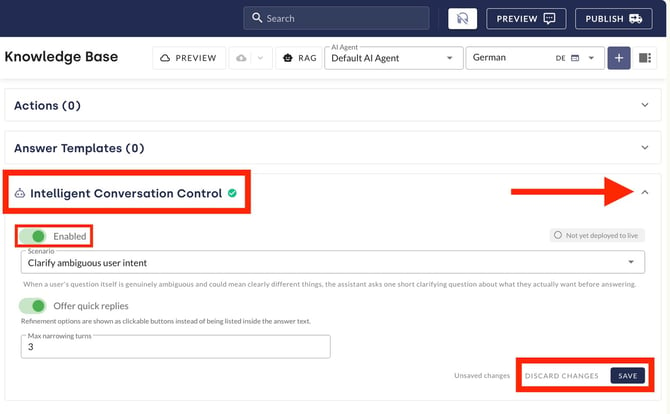
The configuration applies per agent and per channel. For the settings to take effect in the live system, they must be saved in the Hub andthe AI agent itself must be set to live.
Changes made can be reset via Discard changes or activated immediately via Save.
7.1 Clarify ambiguous user intent
This scenario is suitable for situations where a query may have several possible meanings. In such cases, the AI agent asks specific follow-up questions to clarify what the user really means before generating a response.
Example of use:
A customer writes in an online shop chatbot: “I need help with my order.” The term “order” is ambiguous. It could refer to a return, a status enquiry, a change of address or a payment issue.
The AI agent asks specifically: “Is this about the delivery status, a return or a change to the order details?” Users select the appropriate option via a quick-reply button and immediately receive a precise answer without having to rephrase their enquiry.
The AI agent’s behaviour when asking follow-up questions can be further controlled via the instructions. Here, for example, common terms can be defined in advance, such as: ‘The user always means the chat widget when they say “chat”.’ This allows the AI agent to categorise certain enquiries directly without asking unnecessary follow-up questions. Further information on this can be found in the chapter on instructions.
Configuration options:
-
Offer quick replies: If this option is enabled, the AI chatbot presents users with possible answers as quick-reply buttons, i.e. clickable buttons. This simplifies input and speeds up the dialogue.
-
Maximum narrowing turns: Specifies how many follow-up questions the AI agent is permitted to ask. Once this number is reached, the AI agent generates a response in the next step of the conversation, even if the enquiry has not yet been fully clarified. This prevents endless loops of follow-up questions.
7.2 Product and catalogue search
This conversation mode is designed for AI agents that access external data sources via actions, such as a product database or a web search. The AI agent asks specific follow-up questions to narrow down the search query. In addition, a threshold value can be set: if the number of results found is below this value, the AI agent responds directly without asking any further follow-up questions.
To enable the product search, an AI action must be set up. More information on AI actions can be found in this article.
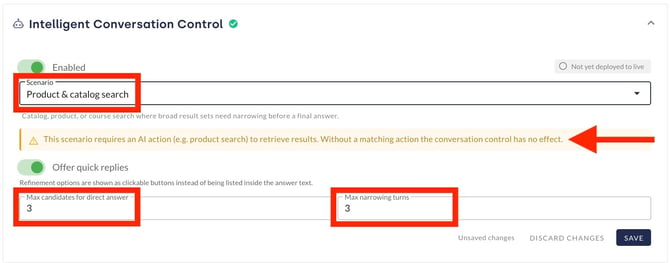
As with the conversation mode for ambiguity, the settings for the maximum number of follow-up questions and quick replies can be configured here.
The instructions can specify the order in which the search filters should be applied and which attributes should be used. In the ‘Online Clothing Shop’ scenario, for example, you could specify that the first follow-up question should always ask for the customer’s gender, followed by whether the customer is an adult or a child, and then, as the third follow-up question, which colour is required.